#시각화 예제2 : duration(전화통화시간) 선 그래프 시각화
(((df['duration'].sort_values()).reset_index()).drop('index',axis=1)).plot()
plt.show()
#1. 선그래프로 데이터의 패턴 분석
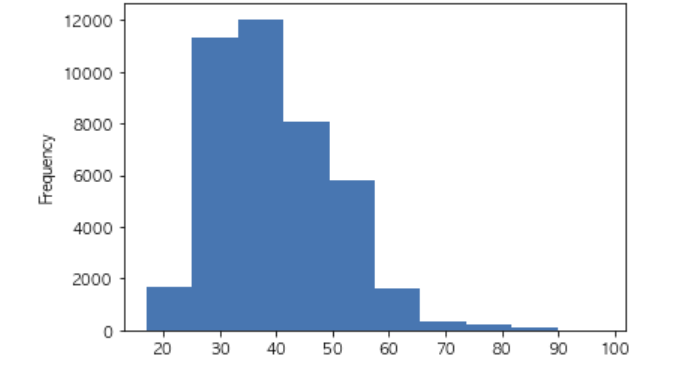
#2. 히스토그램으로 전화통화 시간별 빈도 분석
# 1. 가입여부에 따라 가입한 그룹과 가입하지 않은 그룹으로 나눈다.
#가입여부에 대한 칼럼 : 'y'
#unique()
df['y'].unique()
#groupby사용 - yes, no그룹으로 나뉘게 됨
# 1. 가입여부에 따라 가입한 그룹과 가입하지 않은 그룹으로 나눈다.
#groupby('y')
grouped=df.groupby('y')
# 1. 가입여부에 따라 가입한 그룹과 가입하지 않은 그룹으로 나눈다.
#get_group('yes') - y칼럼이 'yes'인 데이터프레임 추출 - 가입한 그룹만 추출
#get_group('no') - y칼럼이 'no'인 데이터프레임 추출 - 가입하지 않은 그룹만 추출
yes_group=grouped.get_group('yes')
no_group=grouped.get_group('no')
# 1. 가입여부에 따라 가입한 그룹과 가입하지 않은 그룹으로 나눈다.
#yes_group 출력
yes_group.head()
# 1-3. 가입여부에 따라 가입한 그룹과 가입하지 않은 그룹으로 나눈다.
#no_group 출력
no_group.head()
re.sub() 함수는 문자열에서 매치된 텍스트를 다른 텍스트로 치환할 때 사용한다.
‘sub’는 치환을 뜻하는 ‘substitution’의 줄임말이다. 패턴이 여러 번 매치하면 매치한 텍스트를 모두 치환한다.
df['PD_NM'].apply(lambda x : re.sub('\[|\]','', x))
#pd.pivot_table('데이터프레임 변수',values=집계 대상 칼럼, index=행 인덱스가 될 칼럼명, columns=열 인덱스가 될 칼럼명, aggfunc=sum)
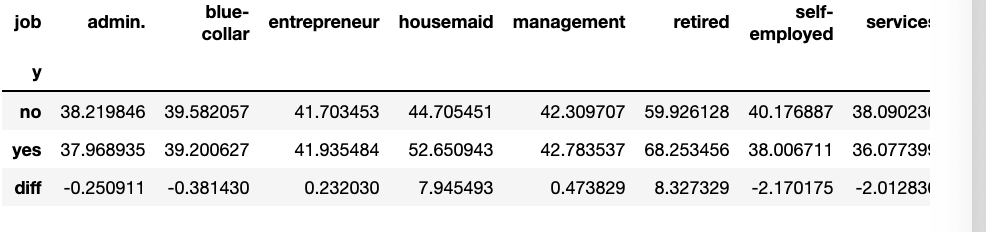
pd.pivot_table(df,values='age',index='y',columns='job',aggfunc='mean')
# 첫 행 삭제
df=pd.read_excel('./data.xls',skiprows=[0])
# 하나의 행 제거
df=pd.read_excel('/Users/junghs/네이버보고서.xls',skiprows=[1])
# 결측치 확인 - 열단위
df.isnull().sum()
# 결측치 확인 - 행단위
df.isnull().sum(axis=1)
# 클릭수 열에 round함수 적용
clk=round(df['클릭수'],0)
# 기존 칼럼데이터 대체
df['클릭수']=clk.astype(int)
df['클릭률(%)']=df['클릭수']/df['노출수']*100
# 반드시 맨 뒤에 *100을 하여서 100을 곱해준다
데이터 프레임을 Dict를 활용해서 간단하게 만드는 법
dict_data={"철수":[1,2,3,4],"영희":[2,3,4,5],"민수":[3,4,5,6],"수진":[4,5,6,7]}
data=DataFrame(dict_data)
#철수 칼럼(데이터프레임의 열 = 시리즈 자료구조) 출력
data['철수']
#count - 각 광고그룹 데이터의 개수
grouped.count()
#mean -각 광고그룹 데이터의 평균
grouped.mean()
#median - 그룹 데이터의 중앙값
grouped.median()
#std - 그룹 데이터의 표준편차
grouped.std()
#var - 그룹 데이터의 분산
grouped.var()